1.1 你面对的是一个什么问题
张伟是一家电商公司的后端工程师。这天早上,他打开电脑,发现 Slack 上有十几条未读消息——全部来自产品经理。
推荐系统在昨晚的促销活动中崩溃了。
张伟打开错误日志,看到程序因为调用层数过深而崩溃。问题出在一个排序函数里。这个函数是他三个月前让 Copilot 写的,当时测试都通过了,谁也没想到它会在数据量大十倍的时候爆炸。
他找到那段代码,看了三分钟,没看懂为什么溢出。他打开 Cursor,输入:"这个排序函数为什么会因为调用层数过深而崩溃?"
Cursor 回答说可能是递归深度太深,建议改成迭代实现。张伟照做了。代码能跑了,但运行速度比以前慢了三倍。
问题解决了吗?张伟不确定。他不知道原来的算法是什么,也不知道新算法复杂度是多少,更不知道会不会在更大的数据量下再次崩溃。
他只是觉得:让 AI 写代码之后,他反而更焦虑了。
这个故事不是个案。
当 coding agent 成为程序员的日常工具,很多人都有过类似的经历:agent 给了一段代码,能跑,但你不知道它对不对、快不快、会不会在某个边界情况下爆炸。
你可能会想:既然 AI 能写代码,为什么我还要学算法?
答案就藏在这个故事里。张伟遇到的问题,不是"写不出代码",而是"不知道代码对不对"。他需要的是判断能力,不是编码能力。
算法能力 = 问题定义能力 + 正确性判断能力 + 复杂度判断能力 + 边界意识。
这一章要教你的,就是这个判断能力。
问题不是从代码开始的
很多人拿到一个任务,第一反应是打开编程工具。但在 agent 时代,你应该先回答一个问题:我在解决什么问题?
这个问题的答案,决定了你给 agent 什么样的提示词,也决定了你如何检验 agent 给你的代码。
让我们从一个具体的场景开始。
假设你的同事找到你,说:"帮我写一个搜索功能,用户输入关键词,返回匹配的商品。"
你会怎么做?
如果你直接把这个描述扔给 agent,你可能会得到一个能跑的代码。但它解决的是你想要的问题吗?
你的同事想要什么样的搜索?
是精确匹配——用户输入"iPhone",只返回标题里正好有"iPhone"的商品?还是模糊匹配——输入"苹果手机",也能返回 iPhone 相关商品?或者智能搜索——输入"拍照好的手机",能根据商品描述推荐?
匹配要不要考虑顺序?搜索"红色连衣裙",是找同时包含"红色"和"连衣裙"的商品,还是找标题里这两个词相邻的商品?
搜索结果怎么排序?按相关度?按销量?按价格?还是按用户的个人偏好?
性能要求是什么?100个商品,1秒返回可以接受?还是100万个商品,100毫秒必须出结果?
这些问题,你的同事可能没说清楚。Agent 可以帮助你补全问题、提出可能的澄清项,但它不能单独承担问题定义的责任。如果你没有判断标准,它生成的澄清问题本身也可能偏离真正需求。
如果你不问清楚,agent 给你的代码可能解决的是完全不同的问题。也许是精确匹配,而你想要的是模糊搜索。也许是 O(n²) 的线性扫描,而你需要的是毫秒级的响应。
任务澄清三问
当别人给你一个任务,不管是"写一个搜索"还是"优化这个函数",你需要问三个问题。我们把它叫做任务澄清三问。
以后每当你面对一个模糊任务,都先不要问"代码怎么写",而是先做一次任务澄清三问。
第一问:输入是什么,输出是什么?
这听起来很基础,但很多人连这个都想不清楚。他们只知道自己"想要一个功能",但说不清这个功能的边界。
搜索功能的输入是什么?是用户输入的字符串。字符串有多长?有没有长度限制?能不能为空?能不能包含特殊字符?
输出是什么?是一组商品。多少个?是全部匹配的商品,还是前 20 个?如果没匹配到,返回什么?空列表?还是推荐热门商品?
这些问题的答案,决定了代码的边界处理。你不能默认 agent 一定会主动追问这些细节,需要先形成自己的规格。
第二问:问题的结构是什么?
问题是搜索?排序?匹配?优化?不同的结构对应不同的算法方向。
搜索问题的特征是"在一组东西里找目标"。如果数据是无序的,你可能需要一个个检查。如果数据已经有序,你可以每次检查中间位置、排除一半范围。如果需要支持模糊匹配,你可能需要提前建立"关键词到商品"的查找表。
排序问题的特征是"让一组东西有序"。如果数据量小,简单方法就够了。如果数据量大,你需要增长更慢的排序方法。如果对稳定性有要求,也就是相等元素的原有顺序不能被打乱,有些排序方法就不能用了。
识别问题的结构,是选择算法的第一步。这一步错了,后面全错。
第三问:约束是什么?
时间约束:必须在多久内返回结果?用户在等待吗?
空间约束:内存有限制吗?需要存到磁盘吗?
精度约束:需要精确解还是近似解?
这些约束决定了什么是"可接受"的解。没有约束,就没有优化的方向。
举个例子。如果搜索功能需要在 100 毫秒内返回结果,而商品库有 100 万件商品,线性扫描肯定不行——它需要遍历所有商品,太慢了。你需要一个更聪明的数据结构,比如提前建立"关键词到商品列表"的查找表。
但如果商品库只有 100 件商品,线性扫描可能只需要 1 毫秒,完全够用。你不需要复杂的索引,简单的代码反而更好。
从模糊描述到清晰规格
任务澄清三问的价值,在于把自然语言需求变成算法规格。下面是一个对照表:
| 模糊说法 | 清晰说法 |
|---|---|
| 帮我写一个搜索功能 | 用户输入关键词,返回标题或描述中包含关键词的前 20 个商品 |
| 要搜得准一点 | 结果按关键词匹配度和销量综合排序 |
| 要快一点 | 商品量约 100 万,搜索响应时间不超过 100ms |
| 没搜到也别空着 | 无匹配结果时返回热门商品推荐 |
这个表格展示了"任务澄清三问"的实际效果:模糊需求被翻译成了可执行的技术规格。
让我们回到张伟的故事
张伟的排序函数为什么会崩溃?
后来他找到了原因。原来 Copilot 给他的代码使用了一种递归排序:每次选一个基准元素,把数据分成"比它小"和"比它大"两边,再分别排序。这里的"递归"可以先理解成:函数在处理一个大列表时,会继续调用自己处理更小的列表。
问题在于,这段实现总是选择固定位置的元素作为基准。昨晚的商品数据恰好接近有序,导致每次划分都极不平衡:一边几乎没有数据,另一边几乎还是原来的全部数据。于是递归调用层数接近 n,不仅时间复杂度退化到 O(n²),还让程序因为调用层数过深而崩溃。
如果张伟知道这种排序在什么情况下会退化,他就会问 Copilot:"这个实现在已排序的数据上会不会退化?"他就会测试那个边界情况。他就不会在凌晨三点被报警叫醒。
但他不知道。他只知道代码"能跑"。
本节要点
- 模糊任务不能直接变成代码,必须先变成清晰问题。
- 清晰问题至少包括输入、输出、结构和约束。
- Agent 可以生成代码、补充澄清问题,但人必须负责判断问题是否定义正确。
- 算法学习的第一步,不是写代码,而是看清楚自己面对的是什么问题。
课堂练习
把下面这个模糊任务改写成清晰规格:
"帮我写一个自动分组功能。"
请分别写出:
- 输入是什么?
- 输出是什么?
- 问题结构是什么?(搜索?排序?分组?匹配?)
- 约束条件是什么?
- 至少 3 个边界情况。
下面这张图展示了问题澄清的完整过程:
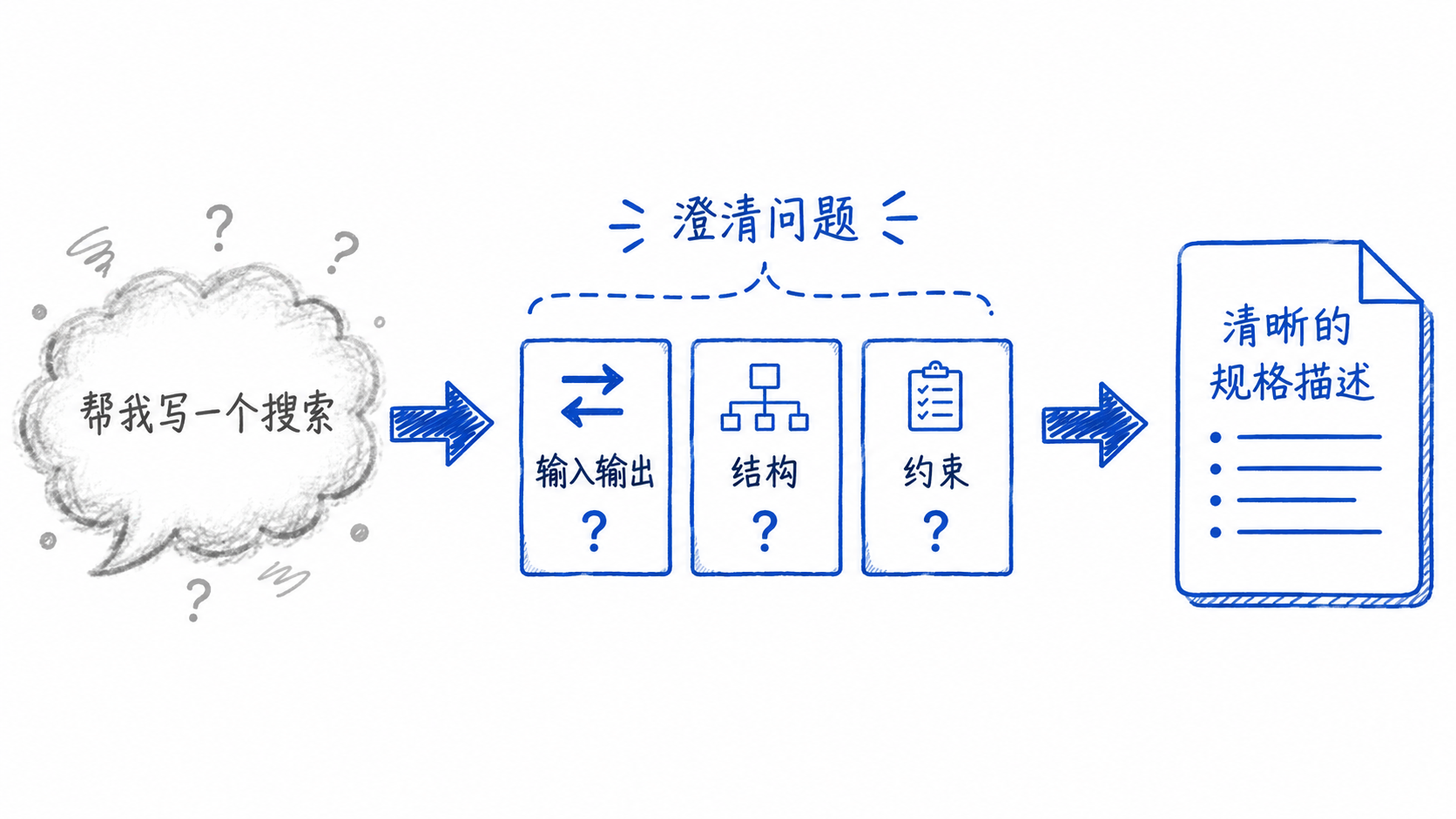
问题澄清工具
下面的卡片可以帮助你把一个模糊任务改写成清晰规格。
你可以输入一个任务描述,然后依次补充输入、输出、数据规模、时间限制和特殊情况。
最终生成的描述,可以直接作为交给 agent 的提示词。
📝 你收到的任务描述
🔍 需要澄清的问题
📋 清晰的问题描述
任务:(请输入任务描述)
输入:(请描述输入格式)
输出:(请描述输出格式)
规模:1,000 级别
时限:100ms 内返回
边界:(未指定)
💡 复杂度建议:初步判断 O(n²) 可能可接受;若每次操作较重,仍需优化
课后测验
📝 课后测验
下一节:1.2 六问诊断法